728x90
반응형
SMALL
스택, 큐, 덱
* 스택(Stack) : LIFO (Last In First Out)

- push : 스택의 맨 위에 요소를 추가, arr.push()
- pop : 스택 top 제거 후 값 반환 , arr.pop()
- top(peek): top제거 하지 않고 값을 반환 , arr[arr.length-1]
- isEmpty : 스택이 비어있는지 확인, arr.length===0
* 큐(Queue): FIFO (First In First Out)
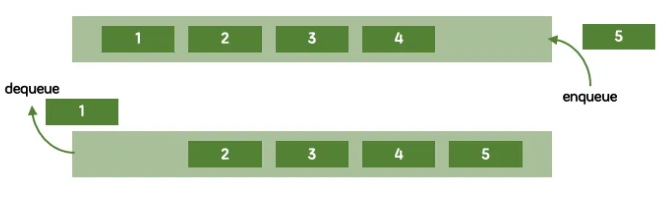
- enqueue : 큐의 끝에 요소 추가, arr.push()
- dequeue : 큐의 앞에서 요소 제거 후 값 반환, arr.shift()
- front : 큐의 맨앞의 요소를 제거 하지 않고 값 반환, arr[0]
- isEmpty: 큐가 비어있는지 확인, arr.length===0
* 덱(Deque) : 양쪽 끝에서 추가 및 제거가 가능한 자료구조로, 스택과 큐의 일반화된 형태

- addFront:덱의 앞쪽에 요소 추가, arr.unshfit()
- addRear: 덱의 뒤쪽에 요소 추가, arr.push()
- removeFront : 덱의 앞쪽에서 요소 제거하고 그값을 반환, arr.shft()
- removeRear: 덱의 뒤쪽에서 요소 제거하고 그 값을 반환, arr.pop()
- isEmpty:덱이 비어있는지 확인, arr.length ===0
스택, 큐, 덱 요약

그리디 알고리즘
* Greedy Algorithm (탐욕 알고리즘)
: 최적해를 구하는 데에 사용되는 근사적인 방법으로, 여러 경우 중 하나를 결정해야 할 때마다 그 순간에 최적이라고 생각되는 것을 선택해 나가는 방식으로 진행하여 최종적인 해답에 도달하는 알고리즘
- 순간의 선택은 최적이지만, 그 선택들을 계속 수집 --> 최종적인 해답을 만들었다고 해서, 그것이 최적이라는 보장은 없음
* Greedy Algorithm 두 가지 조건
- 탐욕 선택 조건(Greedy Choice Property)
- 앞의 선택이 이후의 선택에 영향을 주지X
- 각 단계에서 '최선의 선택' 을 했을 때 전체 문제에 대한 최적해를 구할 수 있는 경우
- 최적 부분 구조 (Optimal Substructure)
- 문제에 대한 최적해가 부분문제에 대해서도 역시 최적해
- 전체 문제의 최적해가 '부분 문제의 최적해로 구성'될 수 있는경우


* Greedy Algorithm 조건 성립 X
- 조건이 성립하지 않는 경우? 탐욕 알고리즘은 최적해를 구하지 못함
하지만, 이러한 경우에도 탐욕 알고리즘은 근사 알고리즘으로 사용 가능할 수 있음. - 근사 알고리즘 (approximation algorithm) 이란? 어떤 최적화 문제에 대한 해의 근사값을 구하는 알고리즘, 이 알고리즘은 가장 최적화되는 답을 구할 수 는 없지만 비교적 빠른 시간에 계산이 가능하며 어느 정도 보장된 근사해를 계산할 수 있다.
- 어떤 특별한 구조가 있는 문제에 대해서는 탐욕 알고리즘이 "언제나" 최적해를 찾아낼 수 있음 => "매트로이드"
* Greedy Algorithm 문제 해결 단계
- 선택 절차 ( Selection Procedure) : 현재 상태에서의 최적의 해답 선택
- 적절성 검사(Feasibility Check): 선택된 해가 문제의 조건을 만족하는지 검사
- 해답 검사 (Solution Check): 원래의 문제가 해결되었는지 검사, 해결되지 않았다면 선택절차로 돌아가 위의 과정을 반복
- 코테 문제 접근 : 실전에서 그리디로 푸는 문제임을 생각하기가 어려움 -> 그리디 문제를 풀면 그리디를 사용한 이유를 설명하는 버릇을 들이고 반례를 찾는 연습을 해야함!
재귀 알고리즘
* 재귀란? 원래의 자리로 되돌아가거나, 되돌아오는 것 | 자기자신을 호출하는 절차
* 재귀함수: 종료조건이 있어야하며, 종료조건을 설정하지 않으면 무한 반복.
- 자기자신 호출시 스택영역에 계속 누적됨
- 필수요소: 문제를 같은 형태의 더 작은 문제로 쪼개야 하기 때문에 패턴을 찾아야 한다.
* 탈출, 종료 조건 (base case, base condition)
- 적어도 하나의 recursion에 빠지지 않는 경우가 존재해야 한다.
- 탈출조건(base case)이 없는 경우, 무한 반복되어 스택 오버플로우 현상 발생
- base case : 더이상 문제를 쪼갤 필요가 없는 경우
- recursive case: 문제를 쪼개서 풀어가는 경우
- 순환을 반복하다보면 결국 base case로 수렴해야한다.
- 탈출조건이 없는 경우, 끝없이 자기 자신 호출 => 최대한 작게 쪼갠 후 문제 해결하는것이 중요
* 문제 예시
- 배열 합 리턴하는 함수 arrSum
- 팩토리얼
- 문자열 뒤집기
function arrSum (arr) {
// 빈 배열을 받았을 때 0을 리턴하는 조건문
// --> 가장 작은 문제를 해결하는 코드 & 재귀를 멈추는 코드
if (arr.length === 0) {
return 0
}
// 배열의 첫 요소 + 나머지 요소가 담긴 배열을 받는 arrSum 함수
// --> 재귀(자기 자신을 호출)를 통해 문제를 작게 쪼개나가는 코드
return arr.shift() + arrSum(arr)
}
arrSum([1, 2, 3, 4, 5]);
function factorial(x) {
if (x < 0) return;
// base case
if (x === 0) return 1;
// recursion case
return x * factorial(x - 1);
}
factorial(3);
function revStr(str) {
if (str === '') return '';
return revStr(str.substr(1)) + str[0];
}
revStr('cat')DFS, BFS
더보기
* 그래프란?
- 여러 노드와 간선으로 연결된 네트워크 또는 자료구조
- 그래프(Graph)는 노드(Vertex)와 간선(Edge)으로 이루어짐 G = (V,E)
- 차수(Degree)는 해당 노드에 연결된 간선의 수
* 그래프의 종류
- 무방향 그래프/ 방향그래프 : 간선에 방향이 있거나 없음
- 가중치 그래프 : 간선에 비용이 할당됨
- 완전 그래프: 모든 노드가 서로 연결됨
- 비연결 그래프 / 연결 그래프
- 순환 그래프 / 비순환 그래프
* 그래프의 종류
- 깊이 우선 탐색(DFS)
- 너비 우선 탐색(BFS)
* 깊이 우선 탐색 (DFS ; Depth Frist Search)
- 한 노드의 자식을 끝까지 순회한 후 다른 노드 순회
- 자식 우선
- 스택(LIFO) 사용

// 그래프를 인접 리스트로 표현
const graph = {
A: ["B", "C"],
B: ["D", "E"],
C: ["F"],
D: [],
E: ["F"],
F: []
};
// DFS 함수
function dfs(graph, startNode, visited = new Set()) {
// 방문 처리
visited.add(startNode);
console.log(startNode); // 방문한 노드를 출력
// 인접 노드 순회
for (const neighbor of graph[startNode]) {
if (!visited.has(neighbor)) {
//여기서 set으로 인자를 넘기는 이유는
//배열 includes 메서드는 순차적으로 검색하기 때문에 O(n)이고
//Set has 메서드는 있는지 검색하기 위해 O(1)의 시간복잡도를 가져 성능면으로 더 좋기때문
dfs(graph, neighbor, visited); // 재귀 호출로 깊이 우선 탐색
}
}
}
// 시작 노드를 'A'로 설정하고 DFS 호출
dfs(graph, "A");DFS의 장단점
장점
- 일정행동을 반복하는데, 이를 만들어놓고 끝까지 계속 돌려 쓰는 것이기 때문에 비교적 간단하게 코드 구현 가능
- 현 경로상의 노드들만 기억하면 되므로 저장공간 수요가 비교적 작음
- 목표 노드가 깊은 단계에 있을 경우 해를 빨리 구할 수 있다.
단점
- 해가 없는 경로가 깊을 경우 탐색시간이 오래 걸릴 수 있다.
- 얻어진 해가 최단 경로가 된다는 보장이 없다.
- 깊이가 무한히 깊어지면 스택오버플로우가 날 위험이 있다. (깊이 제한을 두는 방법으로 해결가능)
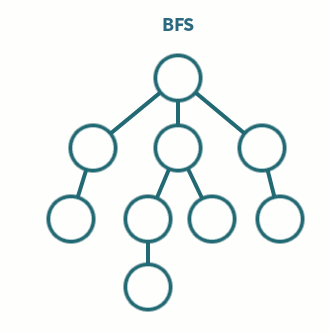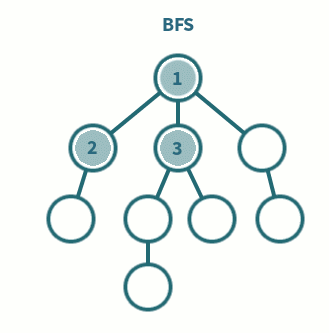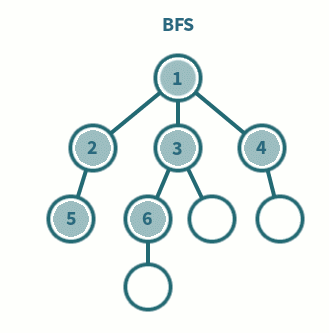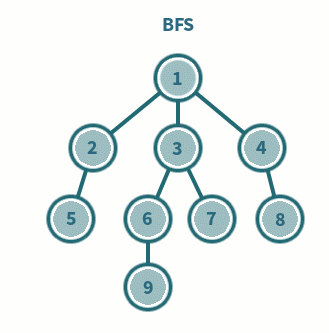
* 너비 우선 탐색 (BFS ; Depth Frist Search)
- 한 단계씩 내려가면서 같은 레벨에 있는 노드들을 먼저 순회
- 형제우선
- 큐(FIFO) 사용
-
// 그래프를 인접 리스트로 표현
const graph = {
A: ["B", "C"],
B: ["D", "E"],
C: ["F"],
D: [],
E: ["F"],
F: []
};
// BFS 함수
function bfs(graph, startNode) {
const visited = new Set(); // 방문한 노드를 저장할 집합
const queue = [startNode]; // 탐색을 위한 큐, 시작 노드를 초기 값으로 설정
visited.add(startNode); // 시작 노드를 방문 처리
while (queue.length > 0) {
const node = queue.shift(); // 큐에서 노드를 꺼내옴
console.log(node); // 방문한 노드를 출력
// 현재 노드의 인접 노드를 순회
for (const neighbor of graph[node]) {
if (!visited.has(neighbor)) { // 아직 방문하지 않은 노드만 탐색
visited.add(neighbor); // 방문 처리
queue.push(neighbor); // 큐에 인접 노드를 추가
}
}
}
}
// 시작 노드를 'A'로 설정하고 BFS 호출
bfs(graph, "A");BFS의 장단점
장점
- 비교적 효율적인 운영이 가능하고, 시간/공간 복잡도 면에서 안정적이다.
- DFS 같은 경우에는 정답을 찾는데, 바로 구할 수 있는 것도 돌고 돌아서 찾아낼 수 있지만, BFS는 그래도 예상한 부분에서 나오게 된다.
- 최단 경로를 구할 수 있다. (단, 간선의 비용이 같을 경우)
단점
- 구현이 비교적 까다롭다.
- DFS와 달리 큐를 이용하여 다음에 탐색할 정점들을 저장하므로 더 큰 저장공간이 필요하다.
DFS, BFS 정리
- 메모리 사용량 : DFS < BFS
- BFS의 경우 인접한 노드들을 모두 큐에 담기 때문에 불필요한 메모리를 잡아 먹게 된다. 인접한 노드들을 모두 큐에 넣는 과정에서 오버플로우가 발생할 수 있다.
- 속도 : DFS < BFS
- 시간복잡도 : DFS와 BFS는 노드 수 + 간선 수 만큼의 복잡도를 지닌다. 즉, O(n)
(단, 구현 방식에 따라 약간씩 달라질 수 있다) - 언제 무엇을 사용 해야 하는가? 그래프가 정말 크다면 DFS가, 최단 거리 계산 시에는 BFS가 좋다.
- 경로의 특징을 저장하는 등의 로직이 더 필요한 경우 DFS 사용
- DFS, BFS의 시간 복잡도는 같기 때문에 중 뭐가 더 낫다고 볼 순 없고 상황에 맞게 사용하면 된다.그래프의 모든 정점을 방문해야 한다면 BFS, DFS 둘 다 상관 X
LIST
'CS > 알고리즘' 카테고리의 다른 글
| [월간 코드 챌린지 시즌2] PGS lv2. 괄호 회전하기 (0) | 2025.09.07 |
|---|---|
| [완전탐색] PGS lv2. 카펫 (0) | 2025.09.07 |
| [백트래킹] PGS 여행경로 (0) | 2024.05.20 |
| [백트래킹] DFS 소수 찾기 (0) | 2024.05.14 |
| [DP] PGS 등굣길 (0) | 2024.05.13 |



